Comparisons of CA-based Spatial Filtering Algorithms¶
Compare computation strategies of spatial filters¶
Accordng to the LS framework, except \(\mathbf{L}_\mathbf{E}\) that has same functions for all methods, other parameters have different forms and functions. The spatial filtering computation strategies in the existing CA-based methods can be grouped by 5 categories based on the differences of parameters in the LS framework:
How to extract inter-class features, which is related to \(\mathbf{P}_\mathbf{E}\);
How to concatenate data in \(\mathbf{Z}\);
Which data is applied for the spatial filtering computation, which is related to the data types included in \(\mathbf{Z}\);
How to combine intra-class features, which is related to \(\mathbf{L}_\mathbf{K}\);
How to extract intra-class features, which is related to \(\mathbf{P}_\mathbf{K}\).
These computation strategies can be summarized as following image:

Compare utilization strategies of spatial filters¶
All CA-based methods follow the same computation paradigm:
The correlation coefficients of the processed EEG signals and the calibration signals or the SSVEP reference signals for all stimuli are calculated. The correlation coefficients of the m-th stimulus can be computed by
\[\mathbf{r}_m={\left(\widehat{\widehat{\mathbf{W}}}_m\right)^T\widehat{\widehat{\mathbf{Z}}}^T\widehat{\widehat{\mathbf{Y}}}_m\widehat{\widehat{\mathbf{V}}}_m}\left/ {\sqrt{\left(\widehat{\widehat{\mathbf{W}}}_m\right)^T\widehat{\widehat{\mathbf{Z}}}^T\widehat{\widehat{\mathbf{Z}}}\widehat{\widehat{\mathbf{W}}}_m\left(\widehat{\widehat{\mathbf{V}}}_m\right)^T\left(\widehat{\widehat{\mathbf{Y}}}_m\right)^T\widehat{\widehat{\mathbf{Y}}}_m\widehat{\widehat{\mathbf{V}}}_m}} \right.\;,\]where \(\widehat{\widehat{\mathbf{Z}}}\) denotes the reorganized processed EEG signal, \(\widehat{\widehat{\mathbf{W}}}_m\) is the spatial filter of the \(m\text{-th}\) stimulus in the recognition process, \(\widehat{\widehat{\mathbf{Y}}}_m\) is the calibration signals or the SSVEP reference signals of the \(m\text{-th}\) stimulus in the recognition process, \(\widehat{\widehat{\mathbf{V}}}_m\) contains the harmonic weights of the \(m\text{-th}\) stimulus in the recognition process.
The CA-based methods combine all elements in \(\mathbf{r}_m\) for each stimulus.
The stimulus with the highest combined correlation coefficient is regarded as the target.
The major differences are the strategies of constructing \(\widehat{\widehat{\mathbf{W}}}_m\), \(\widehat{\widehat{\mathbf{Z}}}\), \(\widehat{\widehat{\mathbf{V}}}_m\), \(\widehat{\widehat{\mathbf{Y}}}_m\) and the combined correlation coefficients. These strategies can be summarized as four types:
Directly apply the obtained spatial filters and the SSVEP template/reference signals: sCCA, itCCA, ttCCA, TRCA, ms-CCA, ms-TRCA and TDCA. Note: These methods only contain one element in \(\mathbf{r}_m\).
Integrate spatial filters obtained from different methods: eCCA.
Combine spatial filters of multiple stimuli: eTRCA, eTRCA-R and ms-eTRCA.
Assume that the spatial filters of different trials are different, combine these spatial filters of various trials: MsetCCA and MsetCCA-R.
Performance Comparisons¶
By using this toolbox, we can easily test recognition performance of various methods in different datasets. Then, the method with the best performance and the corresponding strategies in each dataset can be found. The following two tables summarize the results:
Methods with highest averaged accuracy of small signal length (0.25s) in five datasets:

Methods with highest averaged ITR in five public SSVEP datasets:

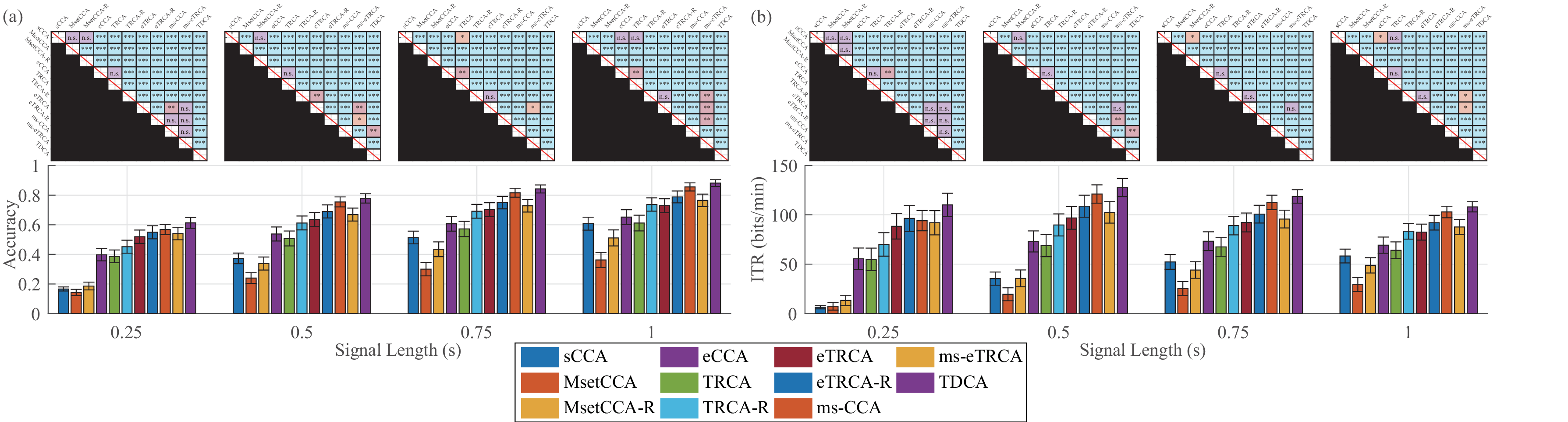
The detailed results are shown below for your references:
Benchmark Dataset:
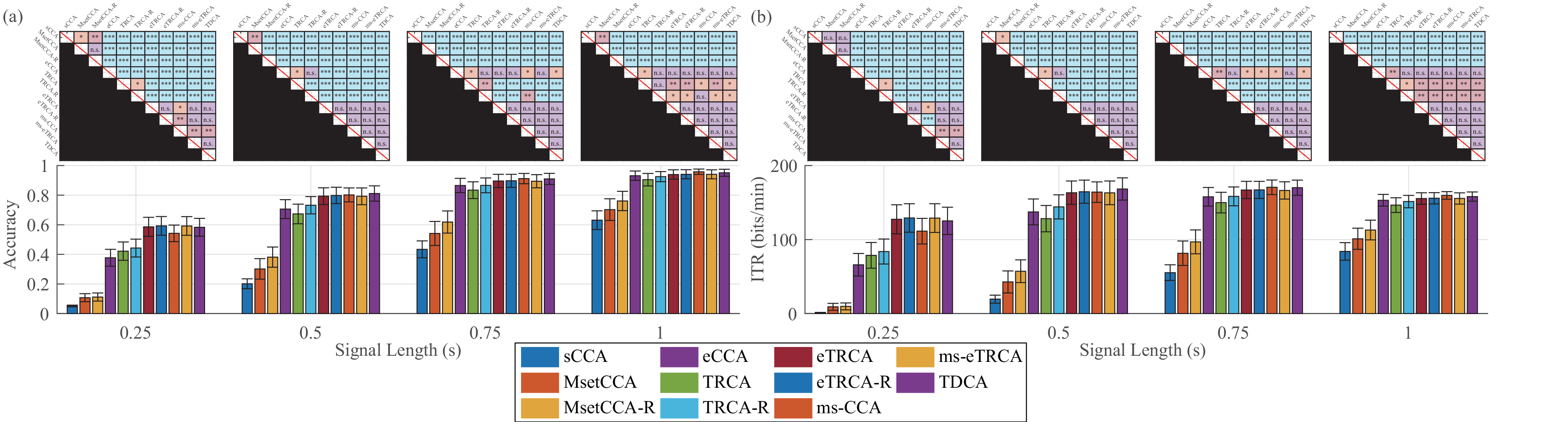
BETA Dataset:

eldBETA Dataset:
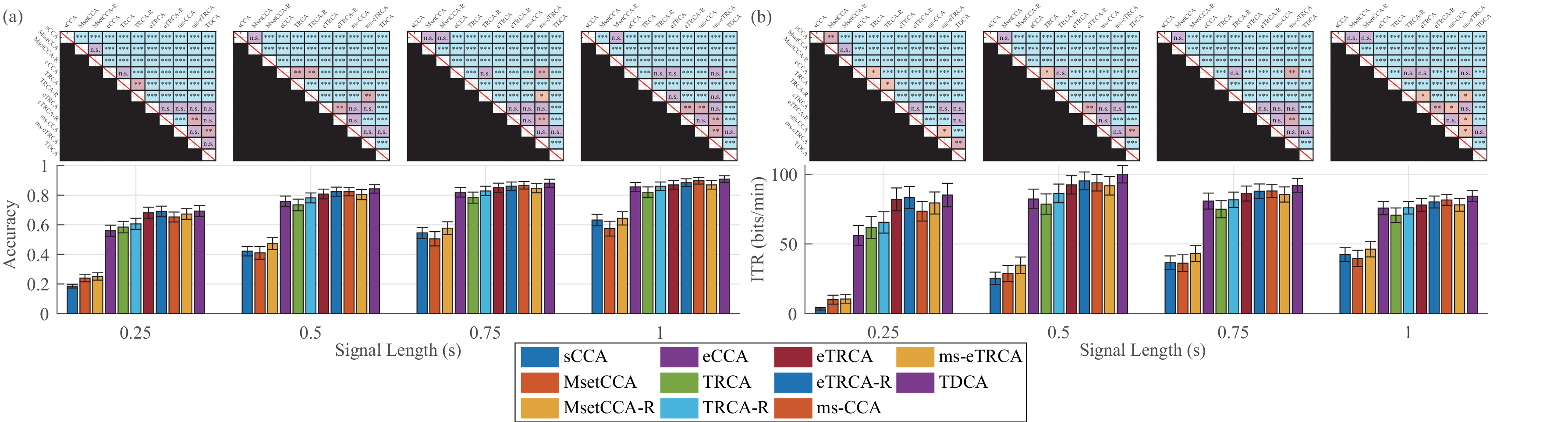
Nakanishi 2015 Dataset:
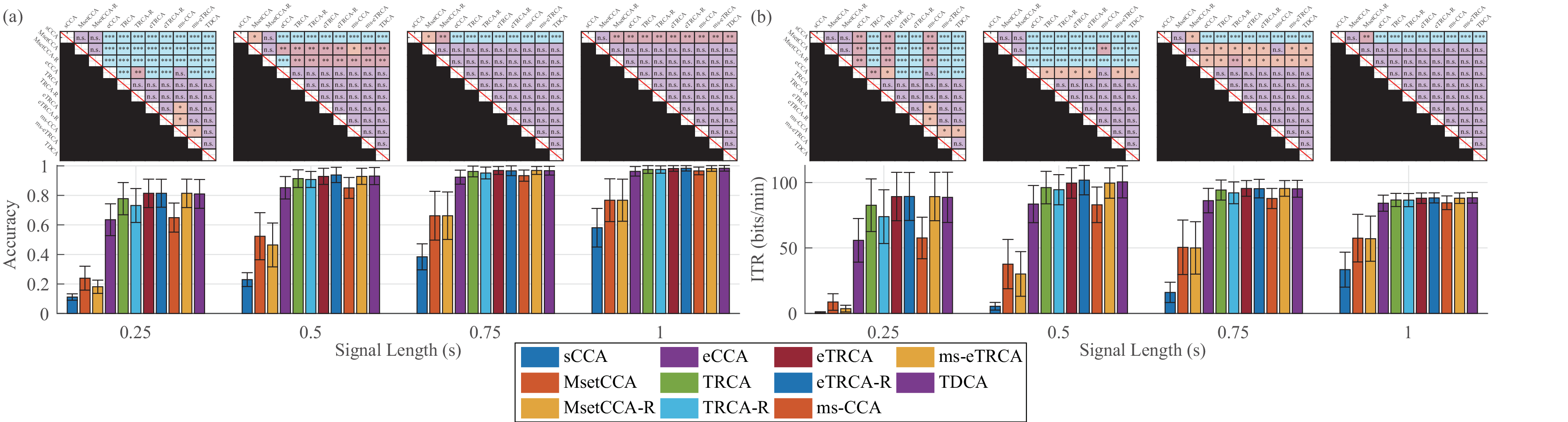
Wearable Dataset (dry electrodes):

Wearable Dataset (wet electrodes):